day by day 24 hr summaries I think is the best balance between file size and granularity. Per chain, per portal is best if possible. I hope to aggregate everything but it may turn out that data is actually smoother (less variation) if limit looking to specific chains or portals
Shouldn’t this be done based on an consistent number of blocks (starting/ending) vs days?
First thing I’m going to do is add all days together, so from that perspective it makes no difference at all. That’s what I will report right away.
After that I want to take a look and see if fine tuning to try to factor out aggregate changes to the system like when RTTM is updated or SSWM is updated or system-wide relay count . I only suggested 24 hrs to match how poktscan already aggregates data (eg “first block that starts after midnight GMT through and including last block to start prior to next midnight GMT.”… that makes it very convenient for me to align your data with aggregate system relay counts in case I want to make an adjustment based on that… it also is the format in which they have given me other data.
But however poktscan want to aggregate is fine with me… I just figure that getting per block data might be unwieldy in terms of file size. Or if they want to just give per block data and not aggregate at all, that is fine too.
@RawthiL Thank you for taking the time to write the proposal and respond to the comments. I read the proposal and skimmed through the many MANY comments on this topic. If I understand correctly, in simple terms, you are proposing to change the rewards given to the nodes that are 15k staked because they are currently earning less than what a 60k node would earn relative to the 4x. Please, correct me if I misunderstood the purpose of this change.
Can you point me to where the documented proof of this is? Not a simulation of “if” but the exact node addresses being compared by the same provider using the same chains, etc. Very possible that I have overlooked it.
Hello Tracie, thats a common missreading that we are trying to solve. We are working on an infographic to show whats exactly our point.
Nodes in the 60K bin are earning 4x what a 15K node earns if both have the same QoS. This has been shown before and it should be completely proved with steve’s experiment.
The problem that we describe is not connected to the stake bins. What we observed is a different impact of the increased number of sessions on the rewards of the nodes that is modulated by the QoS of the nodes. What we showed is that is not correct to assume that if the number of nodes in the network is reduced by two then the number of relays by node will be duplicated evenly for eac h node in the network. This is part of the suppositions of the PUP-21 and it is, according to our metrics, incorrct. The actual distribution of the increment in relays, under a reduced node scenario, seems to be rewarding low-QoS nodes. This, in addition to the inflation-neutral constraint of PIP-22, results in a reduction of the gains of high-QoS 15K nodes.
Thank you for the clarity.
Are you saying “increased sessions for (I assume by influenced you mean poor and not better) poor QoS nodes”? Or are you saying something about the sessions based on the rewards somehow?
I wouldn’t assume this would be the case since the protocol dictates pseudorandomness. If half the nodes on the network consolidate and there are now half the relays up for grabs, I don’t see how they would be distributed evenly.
Perhaps this proposal was premature as there is no real data to provide with it. Since Steve will be providing data with the same QoS nodes, is there someone working on collecting data on the claims here?
Edit to add a question… Please define what you are referencing when you say QoS.
One of the main (expected) effects of PIP-22 was the reduction of nodes in the network. For “increased sessions” I was referring to the increased number of sessions that a node expects to have. To make it clear, if before PIP-22 there were 1000 nodes and after consolidation only 500 remained, the selection probability of the remaining 500 nodes will be twice as before consolidation.
With QoS modulation I was saying that from those remaining 500 nodes, the ones that capitalized more effectively this increase in the selection probability are the low QoS nodes.
It is true, the protocol dictates pseudorandomness for node selection. With half of the nodes each node has twice the probability of being selected for a session. No problem here.
The problem is the interaction of the selected nodes QoS and the Cherry Picker mechanism. The distribution of the relays is never even, it is always modulated by the CP.
We argue that the increase of sessions is affects differently (in relative terms) low QoS nodes and high-QoS nodes. The problem exists, we have measured it using the coefficient of determination. You don’t need to take our word for this. If the distribution was even, this coefficient would have been the same for each QoS group (tables 5 and 22).
We think that the problem roots in the finer mechanics of the CP, when the CP does not know the nodes QoS and when some special conditions are met.
For a low QoS node each session will be always the same:
- High chance of relay serving during CP QoS measuring phase
- Low chances after the CP has identified the high QoS nodes in the session.
For a high QoS node the sessions are more variable:
- Low chance of relay serving during CP QoS measuring phase (compared to next CP phase).
- High chance of being selected after the CP nows that it is a good node.
- Sessions with few relays are not useful as the CP will spend a large portion of the session measuring the nodes.
- Sessions that have pauses of more than 5 min will result in the CP discarding data and begin to measure again.
- Capped rewards due to hitting relay cap in large sessions. In this case the node is removed and all the other nodes will receive more relays.
However this justification is the one that we cannot prove. For this reason we refrain to only claim that the problem exists.
I don’t know if I understand correctly. We provided real world data for our analysis, block data and CP data. The data is historical, from before PIP-22 until September 12. The data is released in the github with the document.
The problem with creating a new dataset is that we would need to observe a large change in the network node count and compare the nodes before and after that change. This is not likely to happen.
When we talked about simulations we were referring to a previous analysis that was hinting that this could happen. This was released during the PIP-22 voting.
For Quality of Service we refer to the node’s relay response time, which is the main feature measured by the Cherry Picker to assign relays.
But the whole point of Steve’s experiment, I thought, was the the QoS on the nodes in Philly ought to be better than the QoS of the nodes in St. L, and if that proves to be the case then can’t the experiment be useful, in part, to help answer the claims of this proposal?
Please note this logical truism: if all bins produce equal rewards within identical high-QoS nodes AND if all bins produce equal rewards within identical low-QoS nodes THEN by corollary, the drop-off in rewards between the high-QoS an low-QoS nodes must be identical for each and every bin
1 Like
I did not understand it that way, I thought that the nodes had all similar QoS, did not check with enough depth, but they were all performing similarly.
If the objective of @steve 's experiment was two measure two groups of nodes with different QoS I think that the QoS variations within the nodes in his group is not big enough to draw any conclusion (I would have notice a big QoS difference I guess).
I don’t know if you are referring to this proposal or Steve’s experiment. If you are referring to the experiment, then yes, it is what I expect to happen.
If you are referring to the issue raised by our document, then no, because this experiment is showing the current status of the network and not how the relative increase of worked relays is connected to the increase of worked sessions.
No, the objective is not to measure QoS - both of the machines should not have QoS issues based on their configuratons. The main reason for the split was to spread the load and I agree the difference in the machines should not make much difference between the groups. I would just look at the perfomance of the stake levels - that’s the point of the test.
ok. In that case we can lump the data from the two server location together and get double the sample size (bin 4 = 30 nodes rather than two separate 15 nodes) and thus reduce random variation by about 30%
I rxd data from poktscan on the dabble experiment and provided some private feedback on that. I will switch attention back to pup-25 and the pdf. Hopefully by Monday I will have some feedback
We have created an infographic to try to explain where is the issue. As I said before the problem for PIP-22 is to keep rewards constant with respect to the rewards before the reduction of nodes.
In the image you will see an example of how a small change in the way the QoS affects the capitalization of the node reduction can lead to big changes in the node gains.
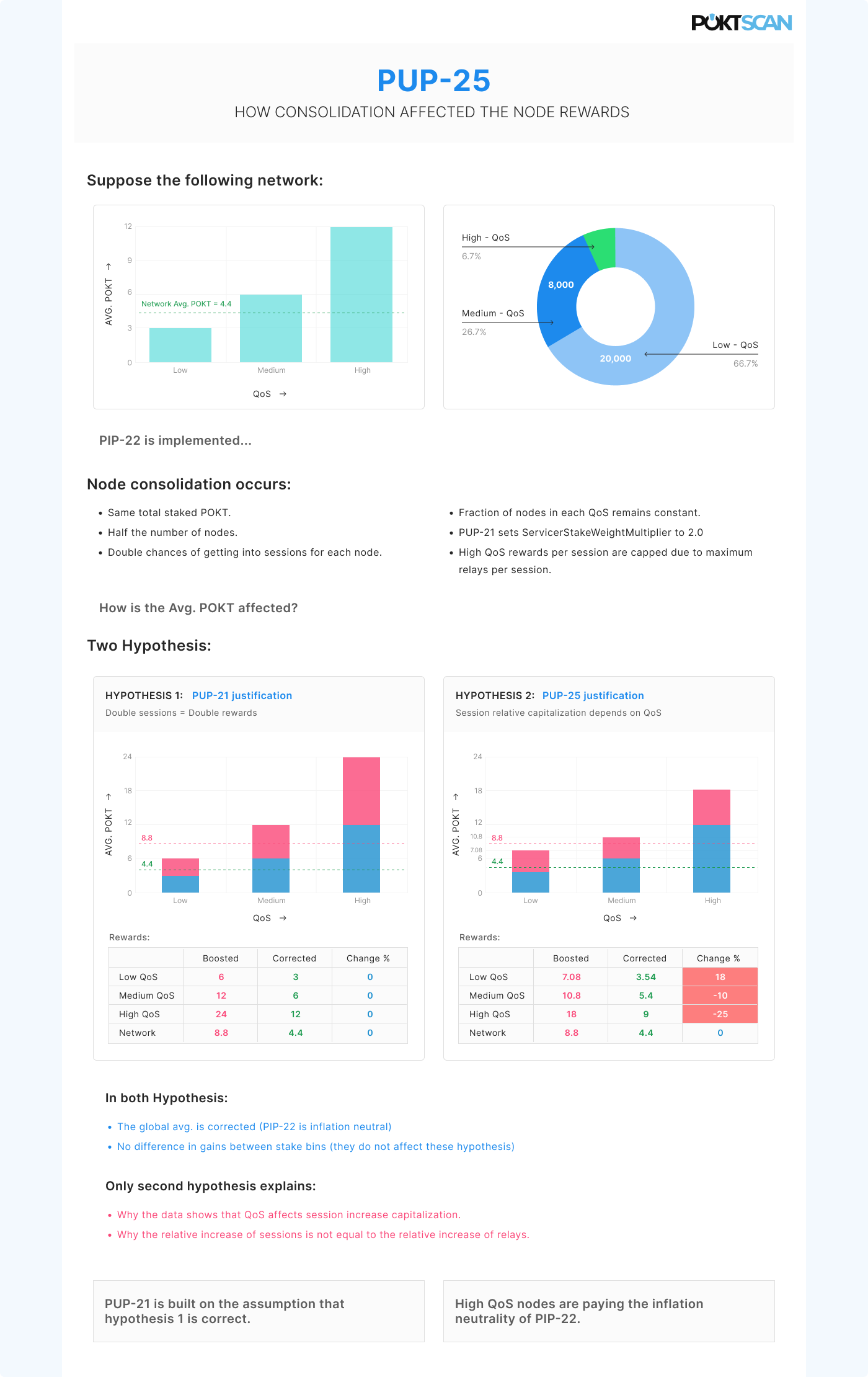
If either hypothesis is true, it is not caused by linear stake weight and cannot be cured by non-linear stake weight.
Please submit a PIP or PUP or PEP which relates to the QOS (IE Cherry Picker).
This proposal should be withdrawn.
1 Like
Yes, the problem is not caused by linear stake weight by itself. It is the effect of the interaction of linear stake weight and the inflation constraints of PIP-22.
If linear stake weight cannot fulfill the constraints of PIP-22 then it should not be used.
And yes, It can be cured by non-linear stake weight, as we shown before. I don’t understand why you say it cannot.
Even if I had cause to believe that your data set were sufficient in size and appropriate in scope, (which I do not) , and if I agreed with your conclusions. I would nonetheless totally disagree with the proposed solution.
Your logic appears to read like:
- more “bad” nodes are in bucket “A” than in bucket “B”
- therefore we should punish bucket “A” and reward bucket “B”
This is an inappropriate solution which, if taken, would not lead to the results you seek. It would simply cause more nodes (good and bad) to move to bucket “B”
If this issue exists, it is a QOS/Cherry Picker issue, and that is where it should be addressed.
This is not a problem of stake buckets. I made it clear in the document and infographic. The stake buckets were never used to justify the unfairness. They were mentioned as secondary problem. I almost regret to mention it, since the focus was put on that part and the rest was ignored.
Forget the stake weight buckets, they are not the root issue.
The issue is that the nodes in the Pocket Network have a large QoS dispersion. Moreover, the majority of the nodes had a bad QoS. This is what creates the problem. With such QoS uniformity, and a non-linear element as the Cherry Picker, it is naive to think that a linear model of the session-to-relays interaction can fit.
I agree with you, this is a QoS problem. If all nodes in the network had a similar high QoS, then this problem disappears (or can be ignored). We are also trying to achieve this, with concrete steps. I believe that we can achieve this with an open and collaborative community.
I also agree that this is a QOS issue.
It should be researched and discussed as a QOS issue.
The fact that you admit it has nothing to do with buckets does not change the fact that this proposal seeks to drastically modify the bucket payment system as a “concrete step”.
Please propose something that address the problem and incentivizes people to improve their QOS rather than just arbitrarily moving money from bucket A to bucket B.
Changing a single parameter that was designed to be changed is not arbitrary. In fact, changing this single parameter does both things, reduces the issue that we are presenting and helps improve the overall QoS of the network (see section 5.3 of the document). The money moving from one bucket to an other is a second order effect.
If you are also seeing the QoS problem, you could help the Pocket Network fix it. I look forward to see a PIP/PEP/PUP/Contribution that helps fixing this issue. I will gladly withdraw my proposal in favor of it.
I do not find this infographic helpful. (1) It just shows some randomly made up numbers in the right column (2) falsely claims that there are no alternative hypotheses to the “pup-25 justification hypothesis” that can explain the data. (3) brings up a thesis that I cannot find anywhere discussed in the white paper, namely “High QoS nodes are paying the inflation neutrality of PIP-22.” Admittedly this thesis is one and the same that @StephenRoss presented his summary of a while back, so I must be missing the right document to review? I have been reviewing the document titled “Non-Linear Servicer Stake Weighting” under the file name “PUP_25_Proposal_Document.pdf” Is there another document I’m suppose to be looking at?
Assuming this is the right document, can you please point to where this thesis is discussed?