Motivation 1: Do no harm. To that end we have specified that the foundation adjust ValidatorStakeWeightMultiplier as needed during the transition period to keep the transition from being inflationary or deflationary (that is to abide by WAGMI principles).
The spirit of that motivation applies to the ServiserStakeFloorMultiplierExponent in the same way. If we tune ServiserStakeFloorMultiplier to keep inflation contant, then we should be able to use all the mechanisms of PIP-22 to meet this goal.
I think that an incentive means that you will receive a reward if you perform an action (consolidation in this case). It does not means that you will be penalized if you do not perform that action.
Setting the exponent above 1 will result in the same long term goal. When the whole network is at the top bin then the multiplier for the top bin will be 1^X = 1.
The 15% (wich is an optimistic value) comes from the flawed setting of the ServiserStakeFloorMultiplier, wich expects the increase of sessions to be equal to the increase of relays (see section 4.5), but this is not true (see section 4.2, the result of equation 12 is not 1).
The problem is related to how the CP is affected by QoS, since lower QoS nodes seem to have a more linear relationship with the number of sessions when compared to the high QoS nodes (figure 6, table 5, section 4.3 and the appendix table 22).
There is no bias in the PIP-22 mechanic, your node will receive the same number of relays regardless the stake amount. The bias rises (probably) from how the QoS affects the CP in an increassed number of sessions scenario (due to compounding).
As I said to Andy, the current linear setting of PIP-22 not only incentivizes nodes to compound, it penalizes the nodes that do not perform compounding. The problem is this last part.
I think that it is not possible to keep the inflation constant and target an specific node count with PIP-22. The model was flawled due to expecting a linear relation between the number of sessions by node and the number of relays by node.
The only way of targeting specific node counts and keep the system fair is by means of the StakeMinimum.
It’s interesting to see this right after @steve said in yesterday’s office hours call that 15K nodes are actually earning a net premium versus their 60K counterparts due to an increase in overall session odds. Maybe he should weigh in here as well.
At the moment, the only thing I’m 100% sure about is that I’m 100% unsure I know what’s going on - with regard to the results of PIP22. So, we’re running the test I mentioned on the node runner call to hopefully get clean / controlled and unbiased data to draw a final conclusion. For transparency, I’ve shared with @RawthiL the details of our test approach, along with the addresses of the 250 nodes we’re using in the test so he and his team can monitor and draw their own conclusion. I plan to also share with the Thunder team to get multiple viewpoints / opinions to keep this as unbiased as possible. I’ve asked them not to share anything publicly until the test is done. This is not intended to hide anything but rather to minimize any more speculations. In hindsight, I probably should have refrained from speculating myself on the call because again, I’m sure I don’t know what’s going on at this point.
Regardless, of the test outcome. I do feel everyone is aligned. We all want to be confident we understand how PIP22 is working and trust that it’s working the way it should.
We, as C0D3R, fully support this proposal. I didn’t do the math, but proposed parameter values doesn’t cause any alarms, either.
Small nodes and large nodes do the exact same work. Large nodes getting up to 4x rewards, and getting those out of small nodes’ pocket (in terms of constantly increasing ServicerStakeWeightMultiplier) is not fair.
Large nodes contribute to the inflation without contributing to its servicing capacity. Purpose of Pocket is not minting tokens. Pocket has a mission, possibly a world changing one. Smaller nodes contribute to this mission more (up to 4x more!) than the mega nodes. Having more nodes in the network is NOT a bad thing provided that they can be run in a cost-effective way. It gives more capacity, more variety (in terms of supported chains and locations), and more resiliency. Let the node runners figure our how to do it efficiently and cheaply.
A well-functioning, robust network needs to be diversified. Today, the only economically sensible option is 60k min stake. Why can’t we reward smaller nodes adequately so that we can have more diversity. 15k nodes have their advantages (such as lower barrier to entry to the network, diversifying assets among node runners, easier time to sell and buy them over OTC, which helps with liquidity). Curbing variety is ultimately not good for the network.
I did do the math. And I suspect you have also.
This proposal (if passed) destroys PUP21’s entire purpose and severely punishes anyone who paid the price to cooperate with the goal of reducing network operating cost and node bloat. It guarantees the permanent adoption of 15k node stake. And I suspect you know that as well. Very sad to see you jump on the spin doctor’s “unfairness” narrative. Those of us who paid the price to help the network are the only ones being treated unfairly here.
If you truly don’t see that, then let’s chat man.
If you look back to the June narrative of PIP-22, you will see that the first version of PIP-22 did not have an exponent or concept of nonlinear weighting. It was suggested at the time that the adjustment factor we now call “ServiceStakeWeightMulitplier” (SSWM) could be set to one value now to incentivize consolidation and adjusted in the future to a different value to incentivize deconsolidation when the network was in need, once again, of expansion.
My first involvement with PIP-22 was to prove that with linear weighting, the economics always favored maximum possible consolidation no matter how many or how little relays per day were serviced by a node and no matter how high or low the costs per node was. I introduced the concept of nonlinear weighting and showed how, unlike SSWM, the optimal consolidation choice was highly sensitive to the setting of this parameter, and therefore was a useful knob to add to PIP-22 to have for the future when expansion of nodes was once again needed.
Now, however, is not such a time. Therefore, we opted not to touch this exponent knob in PUP-21 in order to keep the consolidation question simple for node runners. The exponent is the main complexity added to PIP-22. When it is set to 0.7 or 0.5, for example, the choice to consolidate or not is highly individual depending on balance of rewards and costs. So long as the exponent is set to 1, however. all the guess work of how to optimally deploy one’s POKT under management is removed. No matter if above or below average in relays per day and no matter one’s nodes costing $150 per month or $15 per month, it still comes out more cost effective to maximally consolidate identically configured nodes wherever possible. This was demonstrated in June.
Summarizing the above in a single sentence: The original draft of PIP-22 was linear weighting; we to added a nonlinear knob for the future when we may need it to expand node count but opted not to use it for now. How then can you possibly claim that it was not the intended goal of PIP-22 to maximally incentivize node runners who could consolidate to do so.
Reading the dialogue, I do not think the words “force” and “incentivize” mean what you think they mean. How can you claim PIP-22/PUP-21 forces consolidation when there are currently 20k nodes at 15k? How do you claim that creating an economic structure that favors consolidating over not consolidating to be “unfair” and “forcing” rather than “incentivizing” when that is the very meaning of incentivizing? (I’m only addressing this overreach in your case building; I know I haven’t addressed your 15% concern yet – that will be a separate discussion, which I hope to get to tomorrow)
No! This is highly irresponsible. SSWM can be set “algorithmically” by PNF to meet WAGMI targets precisely because it only affects aggregate rewards and has zero bearing on the internal decision making of a node runner on how to optimally deploy pokt under management.
The optimal deployment strategy, on the other hand is highly sensitive to the value of the exponent. Therefore, algorithmically setting the exponent will cause node runners to constantly be jerked around in trying to keep up with an ever changing “sweet spot” to configure their nodes according to the whims of the algorithm updates.
SSWM is just an extension of RTTM which was already an algorithmically-adjusted PNF parameter, The only reason SSWM exists instead of just setting the one parameter RTTM is (1) because WAGMI/FREN seeks to adjust RTTM on a ~1 month time scale, whereas finer tuning than 1 month is needed during the transition period of PIP-22. and (2) for the convenience to not have to reach back to WAGMI /PUP-13 to redefine the WAGMI procedure for calculating RTTM.
To think you can algorithmically adjust the exponent parameter which gets uniquely applied to each nodes bin value the way PNF algorithmically adjusts the global RTTM and SWWM values is playing with fire.
The non-linear knob was created also for equalizing base nodes rewards, as it is stated by PIP-22:
ValidatorStakeFloorMultiplierExponent closer to 1, whereas if the DAO wants to encourage more horizontal scaling (or equalize rewards for the single node runners) it can set the param closer to 0
The problem is not incentivizing, but penalizing non-compounded nodes.
In every conversation about PIP-22 that I participated, I asked if the idea behind the PIP-22 was to softly increase the minimum stake weight and the answer was NO. I think that the PIP-22 was voted in the spirit of incentivizing consolidation without affecting the base nodes rewards.
It is really clear the difference between incentivizing to perform consolidation and penalizing for not performing consolidation.
From PIP-22 proposal:
Uses Negative Incentives: e.g. increase StakeMinimum to force everyone to consolidate – the number of single node runners is anticipated to be in the thousands and it’s unknown how they’d react to being told that the rules of entry have changed
…
When these debates first started, some core team members gravitated towards stake-weighted servicing since it didn’t introduce either of the first two trade-offs - 1) it is a positive incentive that rewards consolidation rather than penalizing non-consolidation,
Let me ask you, how can you claim that reducing the base nodes rewards is not penalizing non-consolidation?
Regarding the 20k nodes at 15k, this is the current value it does not show anything. The pressure on the lowest bin builds over time, as the largest bin increases.
SSWM has no effect on how to optimally deploy the POKT because there is no strategy, you have to deploy in the largest bin or suffer the consequences.
If the intention is to have a static system where no strategy is to be calculated, then it was irresponsible to introduce the PIP-22 mechanic.
Introducing a model without taking into account the consequences of its implementation is playing with fire. But the rewards model has already been altered by PIP-22, we are just proposing to activate a parameter to remedy an unfairness issue.
The current model does not truly meets its goals of fairness for non-compounding nodes and it has deviations in the inflation goals (only transitory, untill everyone gest to the highest bin).
Again, if reducing the node count is the only objective of PIP-22, then increase the StakeMinimum, simplify the rewards mechanism and be honest with the comunity.
this is a complete misinterpretation of the text. The goal was always to incentivize consolidation during this period of time where we have more nodes than needed. With exponent of 1 everyone gets the exact same rewards per 15k staked so consolidators get the same rewards for less infra cost leading to an incentive to consolidate for everyone who can. Setting exponent to zero causes a 15k node and a 60k node to get the same reward (“equialize reward”), thus incentivizing everyone to de-consolidate and scale horizontally rather than vertically in the future when more nodes are needed. That is the meaning of this sentence.
15k nodes are not penalized. They get the exact same reards per 15k staked as consolidators and have no reduction in rewards compared to June norms, all else being equal (which I will demonstrate in a bit).
I am claiming that base nodes rewards have not been reduced compared to June levels, after compensating for all non-PIP22 related fators (WAGMI reductions, increase to proposer allocation, etc) Again, I will demonstrate this shortly.
A stated goal of PUP-21 was to “keep it simple”. Setting exponent <1 adds a whole layer of complexity of deciding how to optimally allocate POKT under management that, as you point out, disappears for exponent = 1. That should be seen as a huge plus by those complaining that PIP-22 is “too complex”. I’m not sure why you are trying to spin it into a negative. The knob is there for the future when rapid expansion of node count is beneficial, not for now when we are still overprovisioned. That is not being “irresponsible” - I would call that being prudent: having a vision for the future that some day node growth will once again be needed and building a knob now into the PIP-22 code for ability to rapidly respond in the future to changing system needs instead of being caught flat-footed when that day comes and needing to take 2 months to do another code change.
That being said, there obviously still is strategy being used by noderunners, else everyone who could have consolidated would have by now. The 21-day unstaking time and the cap at 4x seem to be reason enough that many noderunners appear to have opted to concentrate for now on other strategies (LeanPocket etc).
It’s sort of like going into a bank to open a CD. They may offer 0.67% APR for a 1 year CD, 1.33% for a 2-year, 2% for a 3-year and 2.66% APR for a 4-year CD. You can complain all you want that the incentive structure is skewed toward the longer lock period, but that is because the longer lock is exactly the behavior the bank is trying to incentivize for the current season, whereas in other seasons it might change or even invert to give higher APR to shorter locks. But no one is forced to lock their money for 4 years. It is a personal choice.
I am really not sure what you are referring to. But as far as PIP-22 and PUP-21 are concerned, I’m pretty sure way more analysis went into this change proposal than just about any recent change, including PUP-11/13 which had way bigger implication on the system than this.
It truly does meet its goals of fairness. As stated above, I will demonstrate this shortly
Finally there is something both of us an agree on! The overarching guidance in PUP-21 was for PNF to reactively adjust SSWM to maintain WAGMI/FREN targets. A suggested methodology was given for setting this value based on chain-weighted avg bin size and Andy provided PNF with a script to do so. PNF stratgey is to adjust SSWM whenever the real-time chain-weighted avg bin differs from current SSWM setting by more than 5%. Right now they differ by 4.2% so there will be another adjustment soon. Next, Andy has identified that his script does not account for unresponsive nodes, and so returns a value that is about 4 to 6% smaller than it would have calculated had unresponsive nodes not been counted . That also needs to be taken into account. Finally there is the effect that you identify where the QoS of consolidating nodes has tended higher than system average. This means that cherry picker probabilities are higher for everyone than if the all the 60k nodes de-consolidated back to 15k nodes. These are the three contributors to hotter-than-desired inflation, and not a single one of these effects favors any bin size over another bin size. Inflation is running hot in exactly the same amount for everyone, from 15k to 30, 45 and 60k nodes. Therefore all that is needed is a bit of a tweak to how PNF sets SWWM, not a complete overhaul in consolidation strategy that, as BenVan already pointed out, would all but kill consolidation in general.
During the first couple weeks of September, the third component averaged about 5 to 11% Never 15%!!). Over the last week this has dropped significantly and no stands near zero. This you can confirm for yourself. The drop is likely due to the evening out of QoS across bins during the last week or so.
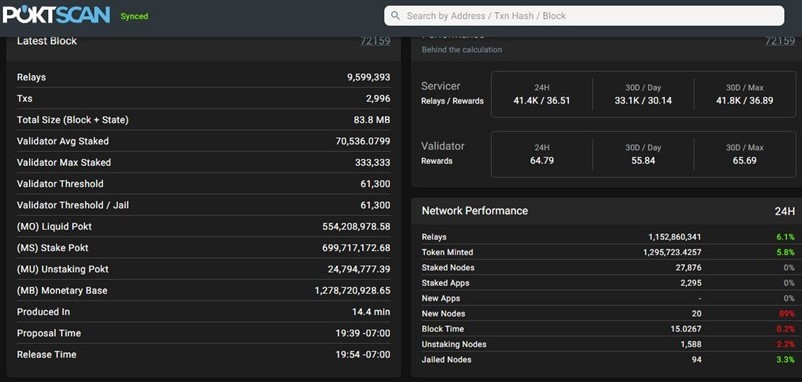
The current lag between actual avg bin and current SSWM setting can be seen here:
Current 24hr relay and token minted snapshot is as follows:
Of which 4.2% is due to the lag between current avg bin and PNF getting around to updating SSWM, and of which another 4% or so is due to the above script not exluding non-responsive nodes. Leaving no inflation or deflation (currently) due to QoS differential across bins
So, I miss intepreted how this exponent should work and “equalize” only means “make rewards equal for all bins”?
If you “equalize” rewards using exponent zero you will apply the same multiplier to everyone (1/SSWM). In this case you will be affecting the inflation and then you will need to change SSWM calculation…
Why would you include that statement there if you could switch off PIP–22 to “equalize” rewards?
I’m not a native English speaker but “equalize” can be interpreted as “to compensate for”.
This was never the issue. I agree with this and the data that you are showing. The problem is that this equality is not compatible with inflation and fairness objectives.
The problem was studied as an static system whithout including the effects of the Cherry Picker and the QoS modulation. The proposel model is correct as long as the effects of the CP and QoS can be neglected. The model is built uppon the assumption that the number of expected relays grows linearly and in the same proportion (regardless the node’s QoS) following the number of expected sessions. This is wrong.
Lets put a simple example, suppose the following:
1- Before PIP-22 there where 10000 nodes.
2- After implementing PIP-22 a group of 3000 nodes decide to unstake to compound.
3- The resulting network now has 7000 nodes (but the same number of staked POKT).
4- There is an increase in the expected number of sessions by node, due to the reduction in the number of nodes.
5- The income of a node that did not perform compounding increases, this must be corrected to keep inflation constant.
6- Apply a reduction of the base node income proportionally to the increase of expected sessions (multiply by ~7000/10000).
The problem is step 6, that is what the PUP-21 is currently doing. That reduction is not correctly justified as the number of relays cannot be predicted by means of the number of sessions and a linear model. The multiplier imposed by PUP-21 does not correlate with the real increment of relays, specially in higher QoS nodes.
Agreed. The overarching guidance of PUP-21 was to adjust SSWM to meet WAGMI emission targets and the suggested methodology to be used should be tweaked to account for the effect you mention. When this second-order tweak to methodology in setting SSWM is applied, the result will be to hit WAGMI emission targets and exactly the right amount of base rewards for 15k nodes as compared to pre-consolidation numbers. I don’t think PNF even needs a PEP in order to make the needed tweak since the overarching guidance of PUP-21 to set SSWM to meet WAGMI targets trumps the suggested methodology. But even if the methodology is to be updated in a PEP, all that is needed is the tweak in how to set SSWM; there is absolutely no need or justification to have to change the exponent at this time except to accomplish the totally separate issue of favoring 15k nodes over consolidated nodes and start the processes of incentivizing nodes that already experienced a 21-day down time, to deconsolidate and undergoing yet another 21-day down time to keep up with the radically-altered reward structure caused by changing exponent to 0.7.
Separately can you please confirm or prove otherwise my assessment that the data over the last week indicates that the second order effect you identify is within a ±5% bound? By my calculation it sits at ±3% with the main uncertainty being the applicability of the completely separate affect that Andy identified where his provided script does not exclude unresponsive nodes (i.e., nodes that are likely excluded from session selection array and therefore ought to be excluded from factoring into the bin average)
I recall that the original referenced repository contained an analysis which concluded that there was insufficient QOS information to draw any conclusion on a per provider basis.
Will need PoktScan to answer what was and wasn’t in the repository. I don’t recall . I’m not so sure about there being an insufficiency of information. I would guess it would be more of a matter of imprudence - not insufficiency of data - to publicly report provider-specific QoS information.
PoktScan graciously provided me some anonymized data so that I could do roll-up QoS analysis. Here is what I have found for median latency on the polygon chain:
Latency (ms)
Asia Pacific
Europe
N. America
End of June
579
268
397
2nd wk Sep
413
211
295
Delta (ms)
(166)
(57)
(102)
Delta (%)
-28.6%
-21.1%
-25.7%
Methodology: (1) For each date and each aws gateway (not all gateway data provided), obtain volume-weighted median latency across 14 anonymized providers. (2) Average this result across all available aws gateways in a region (3 in AP, 6 in EU, 4 in NA) (3) Average this result across last three days in June and again for last three days of provided data, ending ep 12
I don’t know about the other providers, but I was still changing domains and stakes until September 23rd. Since the data is “anonymized” I have know way to tell if it has meaning or not.
Since this proposal claims to
Enable a stake compounding strategy that is beneficial for the quality of service of the network.
I think that getting verifiable, relevant and sufficient QOS data data sets woul be a priority. I spend a decent amount of time tracking the various providers without the benefit of “private” access to gateway logs. It’s not easy and I question how accurately the categorization of the 14 anonymous providers is.
I think that you are not understanding the problem. Please read the report, the problem is not in the QoS of the different bins nor in the return of POKT per POKT invested.
The problem is that the model used to justify the linear modeling is wrong. The linear stake weight model cannot meet the fairnes and inflation objectives at the same time. Right now is only fixing inflation at the cost of unfairness.
We have seen a major change in the network in the last 15 days. The bins QoS is stabilizing, making the original algorithm accurate in its goal of keeping inflation constant. This change has nothing to do with the PIP-22.
This improvement in the QoS dispersion among bins does not change nor invalidates our findings. Our data is from before that time on purpose, to avoid large chages in QoS from affecting the calculations.
I dont know which is the original repository that you mention. Our first report was conclussive and we show a ~30% difference between the expected relays and the simulated relays. That document was disregarded due to been “just a simulation”. That why we are doing it now using only network data.
In our last report we dont make specific claims about QoS because it would have requiered us to model and show such claims (as any claim shoud do). However it can be seen in the report that a difference exists between low and high QoS providers, specifically on how accurate is a linear model based on the increment of relays. This diffence does not tell us that the low QoS nodes can be linearly modeled, it just tell us that a linear model fits better for them than for the high QoS nodes.
The values of the linear determination coeficients (tables 5 and 22)for each group of nodes are clear. The increment of sessions is not linearly related to an increment in relays. Low QoS nodes seem to follow a more linear relationship than high QoS nodes, but we cannot say that they do. The very existance of this difference proves that the linear modeling is not possible since the QoS clearlly affects the increment of relays due to the increment of sessions.
We refrain from posting provider-specific data since some providers may want to keep their numbers private. Node runners are generally secretive regarding their operation and this data could be sensitive.
The included provider were selected by their domain name. Your domain names (benvan*.*) dissapeared from the network. If you have new ones they are too recent to be regarded as “stable”.
The access is not private, many node runners have access to this information. We only collect and save the data (not an easy nor free process).
You can find the aswer to this question on page 16 of the report:
The QoS of the node runners was obtained using the CP data. The av- erage QoS is obtained as an average of the median response time in the different cherry picker gateways, weighted by the gateway number of relays.
which is almost the same proces that @msa6867 descrived earlier:
The only difference is that we also used an average accross all the days under study weighted by the traffic on each day.
This is a response to @msa6867 presentation on the node runners call. The presentation touched some sensitive points of this proposal, some of which are not accurate.
You can hear the presentation here:
and see the slides here:
I will try to keep this as short as possible, since the justifications are all in the document provided with this proposal.
TL.DR:
Mark talks about boosted rewards. They do exists, but they are wrongly estimated.
Multiplying the staked POKT by two means that the rewards are divided by two. Wrong, this is the point that we are proving, it all depends on your QoS. The linear relation does not hold.
In slide 13 an example of how the Cherry Picker assigns probabilities is show. This example only analyzes the CP after it has ranked all the nodes in the session.
Finally it was slipped that we had an “agenda”, not sure what he meant by that. We have disclaimed our affiliations and our business is no secret).
What we find misleading is claiming that:
This is not credible, as @msa6867 is the author of PUP-21 which is being replaced if this proposal passes and he probably also owns nodes which are probably staked at the maximum bin (just a guess but it goes in line with he’s arguments).
(Long version now, you can stop reading if you want)
Mark talks about boosted rewards due to the reduction of nodes, and that this boost disappears when the PIP-22 was activated, due to the base node multiplier.
This is correct, what we are saying is that the applied correction is wrong.
In the presentation an example is given, were the duplication of the staked pocket results in a reduction by half of the served relays (regardless the existence of PIP-22 or not). This is the thesis of the linear model that we talk about in section 4.5. The only difference is that instead of a relation of number of nodes and served relays he uses a relation of staked POKT and minted POKT. We prove that this is wrong.
This conclusion does not take into account how the effects of the QoS on the CP. For this model to be accurate the determination coefficients (D) should be near 1.0, but they are far from it (see table 5 in the main document and table 22 in the appendix).)
In slide 13 an example of how the CP assigns probabilities is show.
The conclusions are correct, there is no change in probability, this is not our point.
The problem here is that the given example is just a snapshot of how the CP works after it has already measured and ranked the nodes. In real life the CP goes to a transitory state were it measures each nodes. During this process the CP gives each node equal opportunity to serve some relays. None of the models provided by @msa6867 take into account this effect, our simulations did.
Although we cannot fully describe the works of this transitory state of the CP, we can measure its effects. During this transitory state is were low QoS nodes receive relays more often (simple math here). Even when this is a short period of the session its effect is not negligible. More sessions means more transitory states for a low QoS nodes, and hence more gains. This can explain the differences observed in the determination coefficients for low and high QoS nodes (once again, tables 5 and 22). Low QoS nodes served relays is more linearly related to the number of sessions, (but what we want is to be fair with high-QoS nodes, not low QoS nodes.). Finally even if this effect were negligible the difference in the determination coefficients cannot be explained by the model used in the presentation.
I’m too stupid to follow all of this and to be frank, I don’t have the time to follow all this. All I can say is our economic and rewards model smell, and it smells very bad. These are the side effects of passing PIP-22. When it comes to the point where our whole community barely understands what’s going on and fundamental software (indexers and statistics tools) takes a lot of time to rewrite/adjust, we should consider taking the more seriously This is tech debt we’re paying, right off the bat.
Thank you Poktscan team in general for digging deeper into the side effects of PIP-22 and taking the time to provide data to back up your claims. Whether it’s actually valid or not, to re-iterate, this whole ordeal is the root cause of a deeper problem.
I can’t confidently support this proposal because I have no idea what’s going on, but at the same time, I don’t want to discredit all the hard work y’all have done to prove this out. That leaves me in a dilemma - and something to consider, as I’m sure I’m not alone here in this. Perhaps, this is a strong indicator we should try to fix the problem at its core - stake-weighted sessions or something even better.
I think you are missing the point. Quite a number of times verbally and in disclaimers on the bottom of the slides I emphasized that what I presented was not yet taking into account the PUP-25 concern re different QoS averages in different bins. Perhaps you and your team understand all the nuances involved, but the average noderunner has been left with confusion and a completely false narrative as a result of the oft-repeated mantra of “unfairness” and 15k nodes being “penalized”. Perhaps the sowing of this confusion was unintentional. Or perhaps it was calculated. I do not know. It was my desire to clear up the misperceptions that exist in the community PRIOR to even being able to begin holding a level-playing-field discussion re PUP-25
True. And the point is??? My perception is that most of the participants on the call have no clue what the technical issue is re different QoS in different bins, and slide 13 was trying to give a simplified pictorial to help those on the call understand how different QoS in different bins can lead to the mint rate being off when calculating SSWM from avg bin size. And you are going to nitpick that I did not crowd every last nuance onto the slide and render it unreadable in the process?
I’d have to go back and listen. I’m pretty sure I was talking re myself that I did not have an agenda or anything to gain one way or the other; I’m pretty sure I didn’t state that your team or service did; and I will continue to refrain from saying that; each evaluator must make that determination for themselves. However, I am more than glad to go on record to say that, IMO, Cod3r’s sugary comment a few days ago in favor of this proposal was completely self-serving, as they are by far the biggest beneficiary of the the POKT reward redistribution that this proposal is seeking to undertake. I believe that @BenVan has already pointed this out in so many words.
Unbelievable! Are you really accusing me of having a bias based on ego to preserve values proposed in PUP-21?? It would have been impossible for me to continue contributing to this ecosystem in the face of some of the community backlash I have received without a thorough dying to ego. The moment I feel any parameter setting in PUP-21 needs changing based on system circumstances, I will be among the first to propose it. And I have been very candid about the need to update the method to calculate SSWM. I have been in discussions with @JackALaing , @Andy-Liquify , @Cryptocorn and @KaydeauxPokt since August 31 on this topic - monitoring, assessing and considering best course of corrective action. But dropping exponent to 0.7??? That, IMO, is not a bona fide “solution” but a complete killing off of consolidation and a return of the system to all 15k nodes. Again, as @BenVan has already pointed out.
If “ego” had really been a factor, you may as well have clamed that since I was the one who all but insisted that the exponent get added to PIP-22 (to have a knob in the future to incentivize de-consolidation) that I would be eager for any chance to change it’s value to exp<1 to justify that the added complexity was a worthwhile add.
I have been completely transparent about my holdings in other places. I have one node staked with a custodian at max bin, but my SLA is pure rev share, so it makes absolutely no difference to me, reward wise, whether that 60k is staked as one 60k node or four 15k nodes. In addition I have some pokt staked with two fractional pool providers, one of which runs 15k nodes almost exclusively and one of which has nodes at all four bin levels. Thus I have absolutely nothing personal to gain from keeping exp=1; rather, a slight edge, if anything in lowering the exponent. But I don’t advocate lowering the exponent, because we are still in a season where we do not need to encourage the growth of node count.