@RawthiL Firstly, ty so much for the detailed response and so promptly!
Next Steps
Below are what I’d suggest as next steps based on the data and discussion available..
Actionable now:
- Gateways: Gateways should re-evaluate how their gigastakes are distributed and used. See the
Gateway Q&A. - DAO: We re-evaluate what an effective
pocketcore/MinimumNumberOfProofsthat helps the network but does not have a considerate impact on the economics (i.e. these will become un-claimable sessions).
Education:
- PNF Education: PNF should take this into consideration as more gateway stakes are distributed (to whom, how much, educating the gateway, etc…). Cc @Dermot
Backup bandaids:
These are last resort backups in case of emergency in order of least impact on network economics/tokenomics.
- Increase
pocketcore/BlockByteSize- Though LeanPOKT makes this less costly, it should not be the immediate go to option for scalability reasons.
- Decrease
pocketcore/SessionNodeCount- Though this will work, it will cost some decentralization and optionality w.r.t gateways managing QoS.
- Increase
pos/BlocksPerSession- Though this will work, the long 15 minute block time we already having, slowing it down even more is not preferable.
Follow-up Questions for @BenVan
@BenVan I have a couple of questions I wanted to follow up on.
-
You mentioned you changed something in your nodes to make sure the network has less bloat. Do you mind sharing & reiterating what that is?
-
@BenVan what are the current ssd storage requirements for a single pocket node for you? It could be a good data point to decide how viable the block size option is.
-
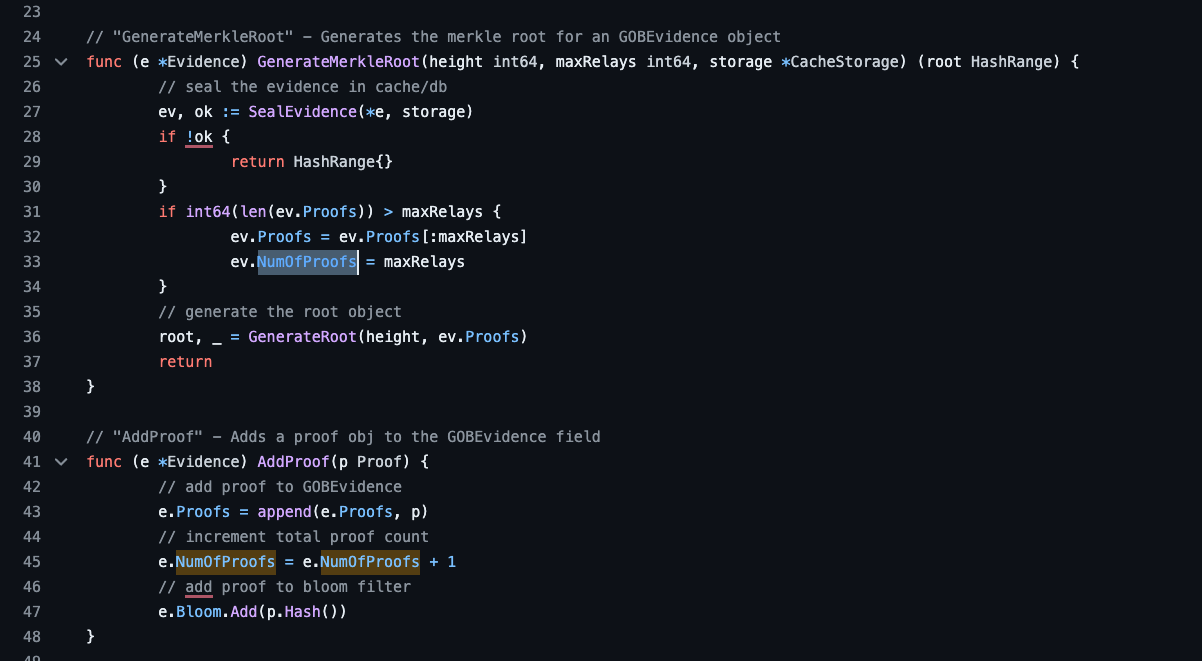
You suggested increasing
pocketcore/MinimumNumberOfProofsto something in the low 10s.
3.1 Am I remembering correctly?
3.2 My understanding from the code is thatNumOfProofsis literally the number of relays, so like @RawthiL said, it has to be in the hundreds to have substantial impact.
Gateway Q&A
Specific data we need to understand w.r.t gateways are:
- How many app stakes are available to each gateway?
- How many of the available stakes are used?
- How are they used w.r.t to stake concentration?
- Is there an opportunity to consolidate stake.
I’ll work on this with the backend team for Grove.
@poktblade Could you look into this on behalf of nodies?
Shannon
Relay Mining (with the relay threshold) will enable a single session to hold billions/trillions of relays by modulating the difficulty.
The Probabilistic Proof document we put together (so not all claims need a proof) will solve this part.
Nits / Questions for @RawthiL
- Add a unit whenever the x-axis is
amountso it’s more self-descriptive - Found a couple small typos that spell-check should catch. E.g.
gruops pocketcore/SessionNodeCountis mentioned twice- Do you know why this link shows
80MBfor the block size: https://poktscan.com/explore?tab=blocks
Context
@BenVan posted the following in #node-chat.

And during the ecosystem call, we decided to collect the following data to understand next steps: