authors:
This is an analysis of current Pocket Network Portal deployment and possible optimal deployment strategies.
We are requesting Pocket Network Inc. (PNI) to reduce the number of portals to reduce the cost of the network and improve the average latency.
Rationale
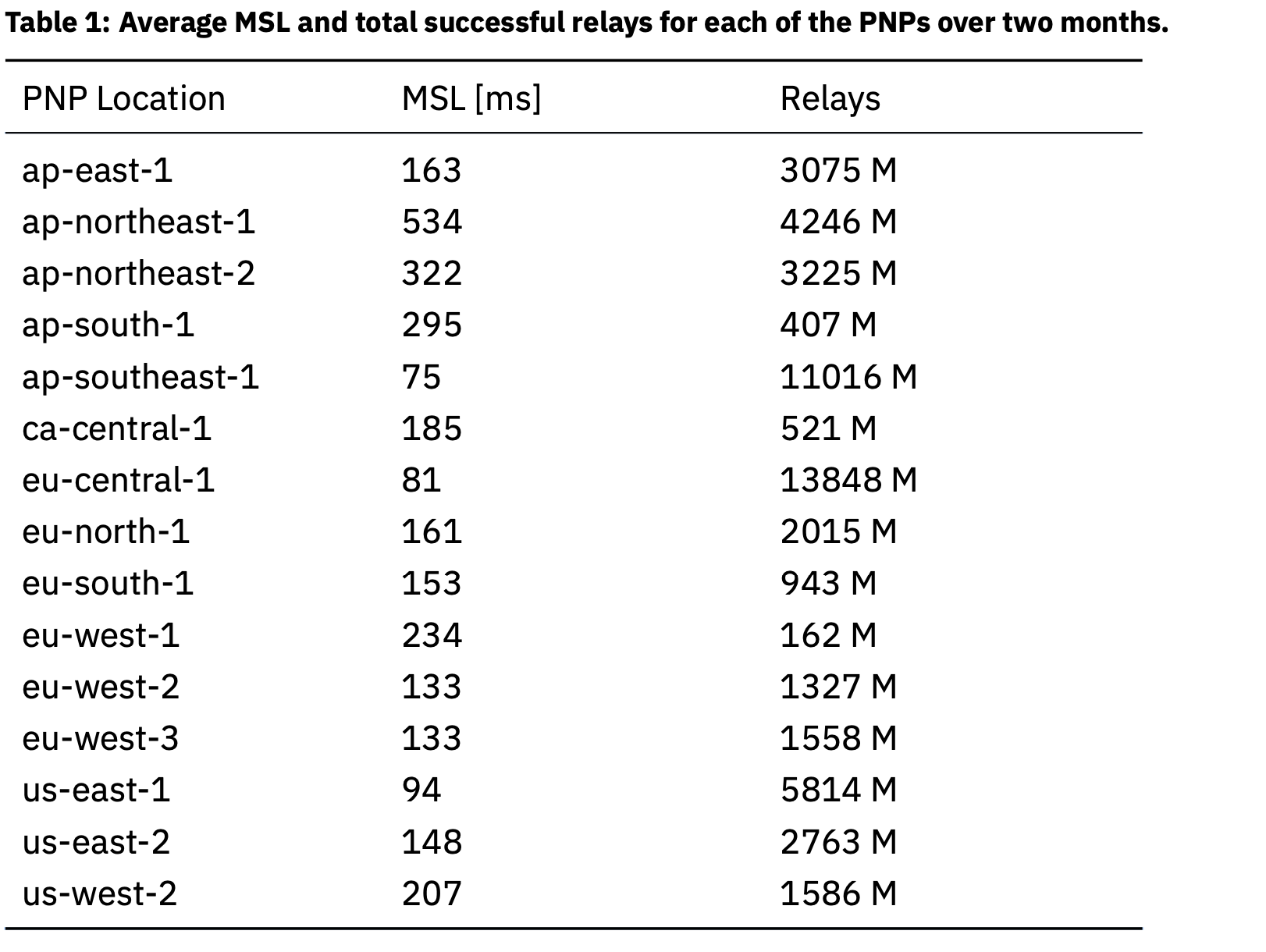
We have been observing the Pocket Network traffic since the Cherry Picker DB was made public (~06/2022) since that date we observed that most of the traffic was flowing through 3-4 gateways.
Accordingly, node runner aligned their nodes to capture most of this traffic. Later, with the introduction of the GeoMesh, the traffic and the node-runners node deployment aligned even further.
Today, when traffic flows from an specific area, there is always a node-runner following this surge, and a node is promptly spin up to catch all this traffic.
This behavior is is being intensified due to the lower rewards and the tighter competition among node runners, resulting in lots of effort put into service of chasing traffic and improve spot-profit detection (single chains deployed in exotic regions).
While this is not a bad thing in itself and it could be regarded as simple node-runner competition, we think that it is not optimal for the Pocket Network interests.
Summary
We are proposing to reduce the number of gateways to minimum/optimal configuration of 3 gateways:
ap-southeast-1us-east-1eu-central-1
This will provide the following benefits:
- Less node-runner effort used to track and chase chains for small gains (both in QoS and rewards)
- Reduced infrastructure costs for node runners (less sell pressure)
- Reduced infrastructure costs for PNI (longer runway)
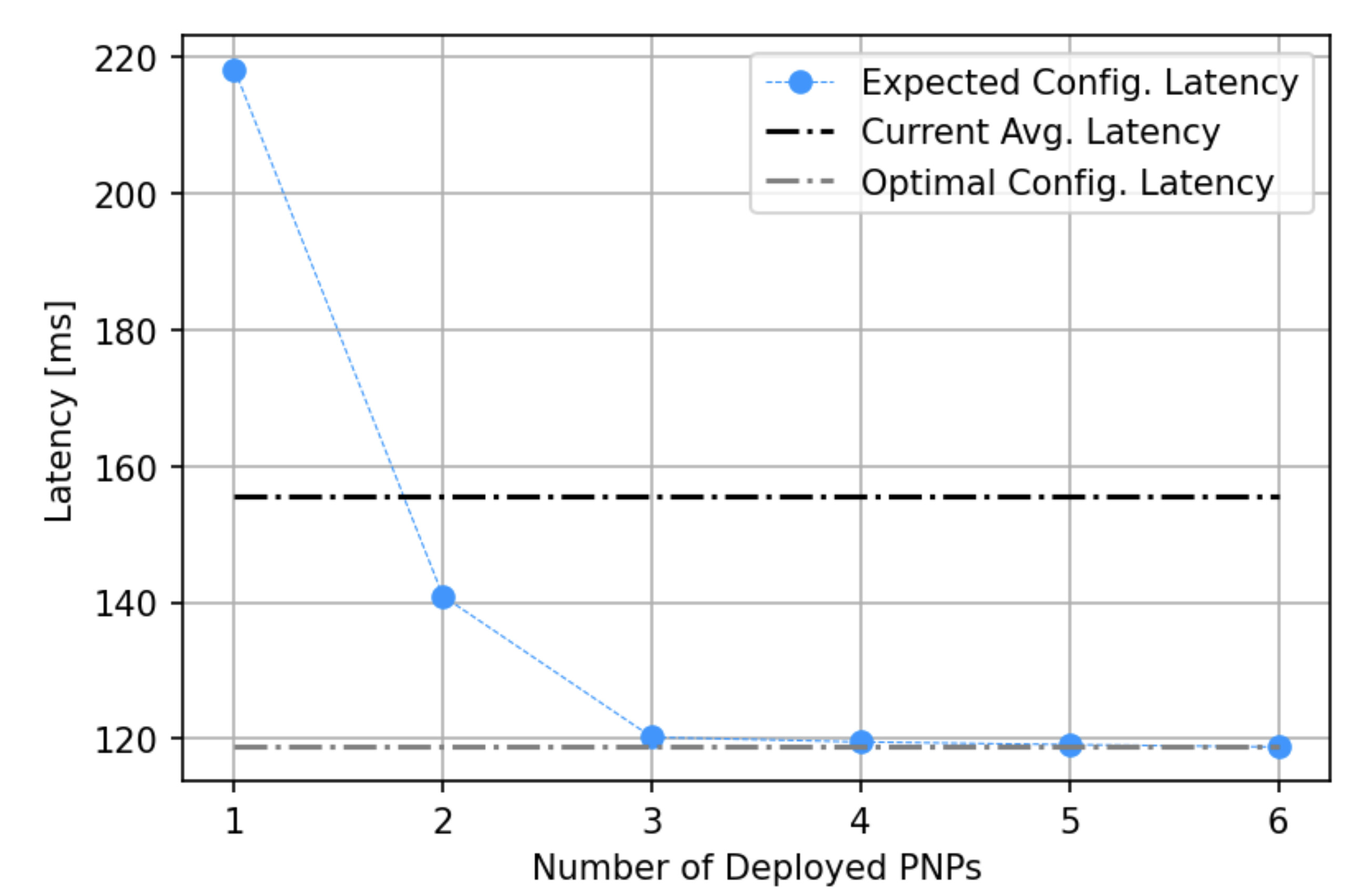
- Reduced global latency. We expect a reduction from
155 msto120 ms(Mean Success Latency) - Network cost becomes easier to estimate (very important for economic models).
- Metrics become easier to track and understand. Cherry Picker metrics are critical to the ecosystem and economic models.
- With fixed number of gateways (until Gateway client) (that the community agrees on having) node runners wont fear further arbitrary retirement of gateways (such as
ap-northeast-1)
Also, we hope that if node-runners are able to reduce the time their spent in chasing traffic they can focus on improving the protocol.
The Pocket Network has many actors with different skill sets, if we can manage to focus them on improving the network instead on focusing on that extra 3% relays, everybody wins.
Metodology
(we encourage the interested reader to go through the full document and code here)
In a few words, the problem is tackled as a linear optimization problem based on a graph structure of the Amazon Web Services (AWS) inner ping times and the node-runners latency to the different Pocket Network Portals (PNP) located on specific AWS Availability Zones.
We show how to model the PNP deployment problem, find an optimal solution and propose a better strategy to reduce the costs for all the players of the Pocket Network ecosystem.
As data we use the Cherry Picker informed latency and the ping data of AWS from Cloud Ping. Also, the cost of “hopping” through AWS regions was modeled, adding 50 ms each time the relays need to cross a node that is not their target node (the servicers).
The initial graph is the following:

What we did was find which were the lines coming from the blue node (servicers) that can be removed and re-routed to obtain the optimal minimum configuration. The resulting map is the following:

Also we produced a graph showing how the latency of the network evolved with the number of active portals:
Open questions for the community
- Are there problems that are not modeled in this report?
- How can we improve this model if it is not realistic enough?